An End-to-end GPT Model for Seamless Voice Conversation
Model Overview
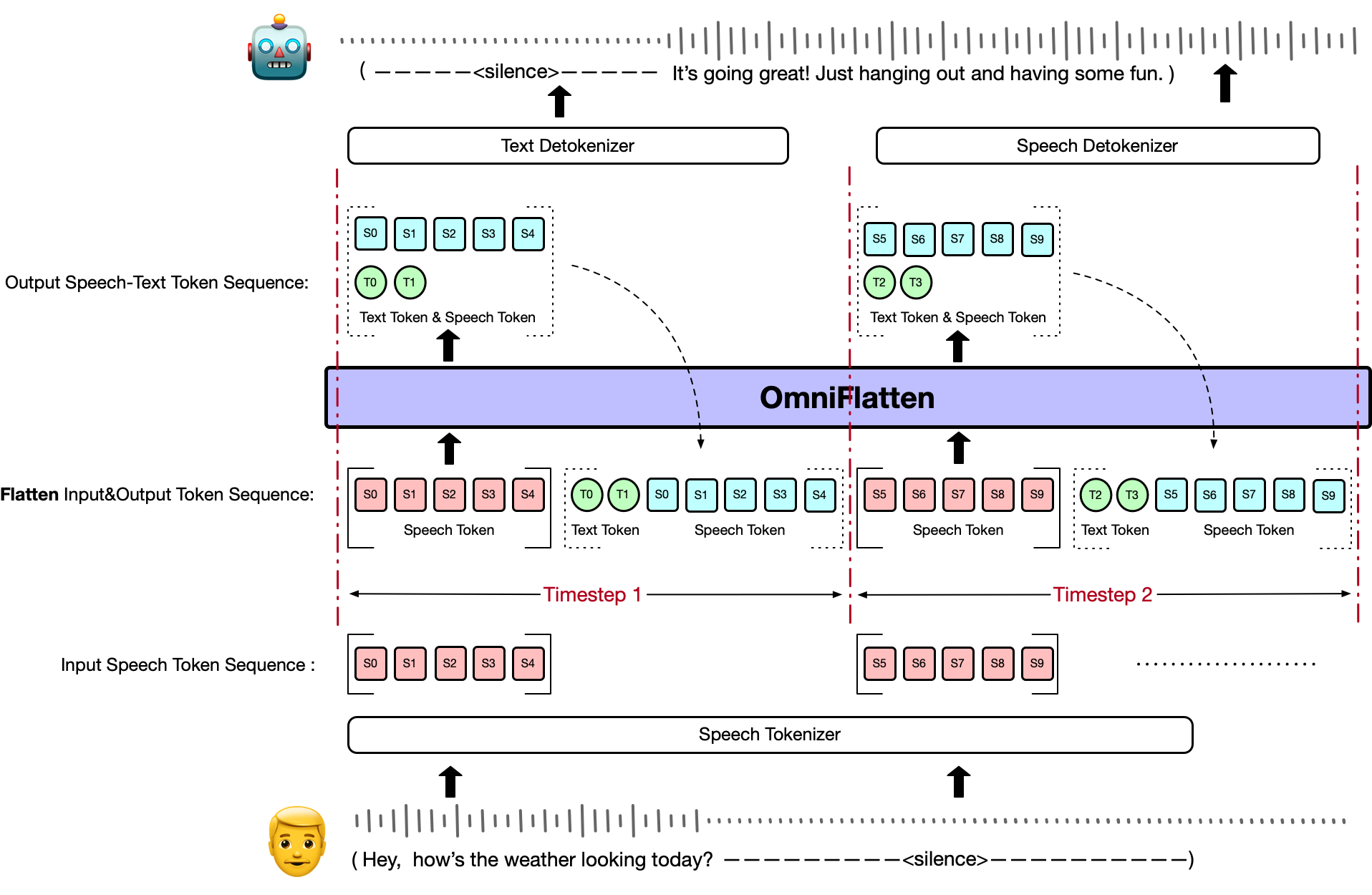
We provide OmniFlatten, a groundbreaking model designed for full-duplex conversation, which
effectively mirrors the complexity and dynamics of natural human dialogue. This model leverages a novel
multi-stage post-training scheme to adapt a large text-based language model into an integrated speech-text
dialogue system that operates in real time. Through progressive fine-tuning, OmniFlatten aligns speech and
text modalities without altering the core architecture, ensuring low latency and seamless interactions. This
approach paves the way for developing more efficient and natural end-to-end full-duplex spoken dialogue
systems.
Experiments
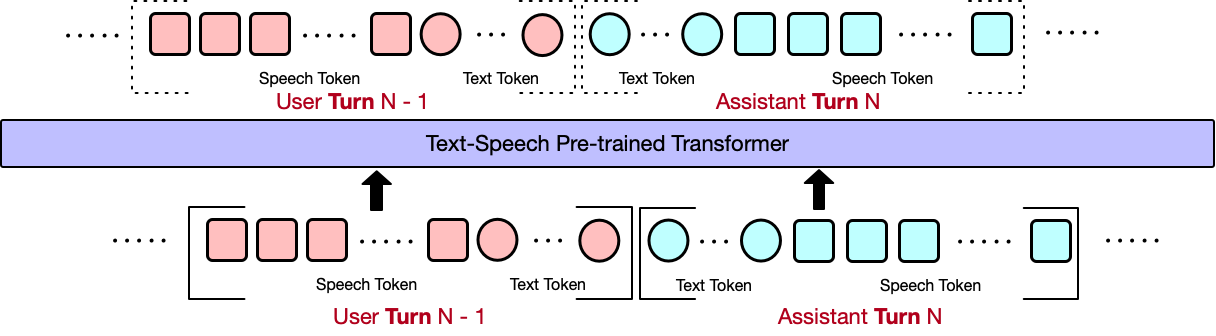
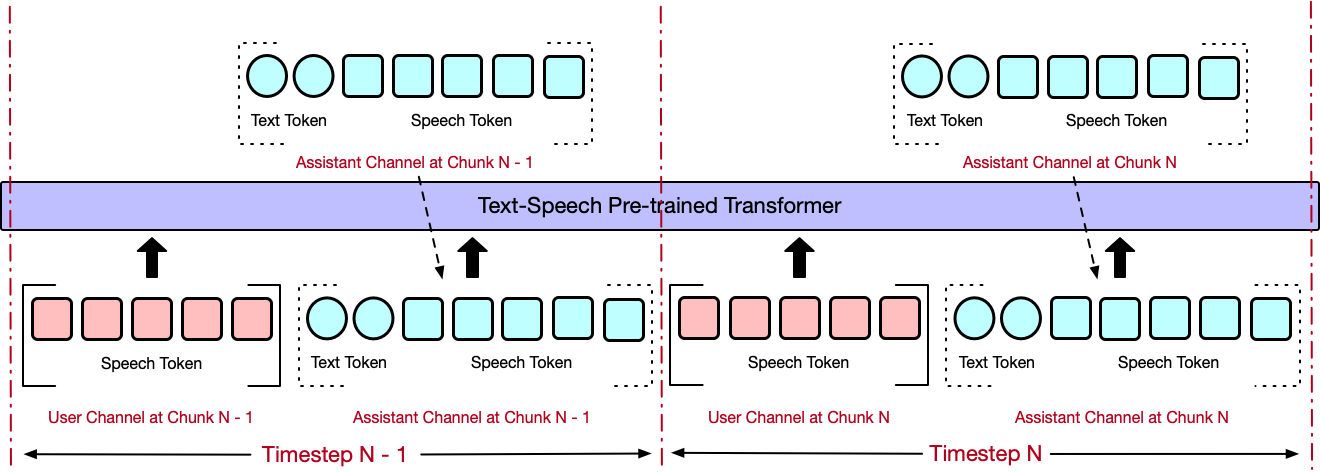
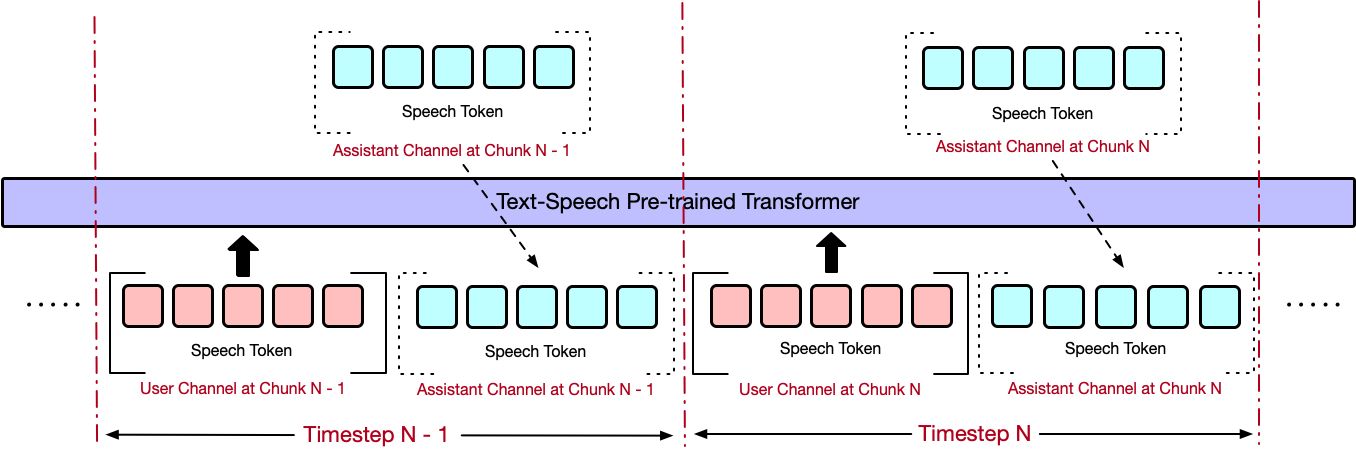
We use a progressive learning approach for model training, adopting Speech-Text Alignment, 4-streaming
training, 3-streaming training, and 2-streaming training.
4-Streaming Training
3-Streaming Training
2-Streaming Training
Cases
We will show you some cases:
Metrics
Speech-Text Alignment
ASR results on Librispeech and Wenetspeech test datasets. For Librispeech, we report the WER
metric. For Wenetspeech, we report the CER metric.
Model
Librispeech
Wenetspeech
test-clean
test-other
test-meeting
test-net
Whisper-S
3.13
7.37
25.62
16.66
Whisper-L
1.82
3.5
18.87
10.48
VITA
8.14
18.4
12.15
16.53
OmniFlatten
7.91
19.21
26.1
19.0
TTS results on LibriTTS and AIShell-3. For LibriTTS, we utilize whisper-large-v3 model to perform
recognition on TTS outputs and assess the WER metric. For AIShell-3, we deploy the paraformer-zh model
to recognize TTS results and evaluate CER metric.
Model
LibriTTS (WER)
AIShell-3 (CER)
Original
2.66
2.52
ChatTTS
8.32
3.87
CosyVoice
2.89
3.82
OmniFlatten
4.51
4.46
Dialogue Capability
Performance results of speech and text chat capabilities in both Chinese and English test
datasets.
Model
Params
English
Chinese
Score (Text)
Score (Speech + ASR)
Score (Text)
Score (Speech + ASR)
Qwen2-0.5B-Instruct
0.5B
6.75
-
6.98
-
Qwen2-7B-Instruct
7B
8.37
-
8.09
-
LLaMA-Omni
8B
6.01
5.50
4.17
3.89
Moshi
7B
3.92
3.46
-
-
GLM-Voice
9B
6.97
6.40
7.02
6.69
OmniFlatten directly 3-stream
0.5B
2.99
2.59
4.94
3.95
OmniFlatten 3-stream w/o half-duplex
0.5B
3.89
3.54
5.25
4.76
OmniFlatten 3-stream full process
0.5B
4.88
3.92
5.6
5.15
OmniFlatten 2-stream full process
0.5B
-
2.19
-
3.06
Ground Truth Response
-
7.65
-
6.83
-
Turn-Taking Metrics
Assistant Turn-taking and User Turn-taking accuracy at the k-th token (Acc@K) and Response Time.